请告诉我们您的知识需求以及对本站的评价与建议。
满意 不满意
Email:
地铁深基坑变形数据的挖掘分析与风险识别
栏目最新
- 低碳节能建筑设计的相关问题及解决方法
- 江苏建筑职业技术学院图书馆设计文化理念
- 四川雅安名山县涌泉村抗震小学的设计理念
- 四川汶川5.12大地震的启示
- 汶川大地震震中纪念馆的创作思考
- 洛阳洛南新区雅安新城结构设计
- 绿色居住建筑的节地设计
- 广州珠江新城海心沙地下空间建筑设计方案
- 黔东南地区郎德苗寨民居的热适应性
- 西气东输工程中长输管道站场建筑模块化设计与应用
网站最新
内容提示:基坑工程的隐患发展成工程事故之前兆,必定表现在监测数据某些特征的异常变化,此时若据此及时采取相应的措施,便能够以很小的代价避免或降低工程风险。以地铁基坑工程的大量监测数据为基础,通过数据挖掘方法寻找工程风险和变形数据特征变化值之间的内在联系和相关规律,以形成量化的评判指标来识别和评价工程的危险程度,从数据分析的角度提供了一种发现和控制工程风险的办法。
摘 要:基坑工程的隐患发展成工程事故之前兆,必定表现在监测数据某些特征的异常变化,此时若据此及时采取相应的措施,便能够以很小的代价避免或降低工程风险。以地铁基坑工程的大量监测数据为基础,通过数据挖掘方法寻找工程风险和变形数据特征变化值之间的内在联系和相关规律,以形成量化的评判指标来识别和评价工程的危险程度,从数据分析的角度提供了一种发现和控制工程风险的办法。(参考《建筑中文网》)
关键词:地铁深基坑;风险识别;数据挖掘
0 前 言
大量工程实践表明,基坑工程发生的工程事故和工程隐患与监测数据的某种波动具有很强的相关性。
基坑在施工过程中表现的各种性态实质上由其内在的力学规律所驱动,可以断定通过监测数据的挖掘分析完全能找到表象数据所隐含的规律。因此以系统收集的数据为基础,研究基坑在施工过程中的变形规律,采用先进合理的数据分析手段,发现监测数据特征和工程危险之间的联系,对于控制今后工程的施工风险,是一项十分必要的工作。
数据挖掘(data mining)是一个很好的理念:从大量的、不完全的、有噪声的、模糊的、随机的数据中提取隐含在其中的、人们事先不知道的或忽视的、但又是潜在有用的信息和知识的过程。随着信息技术的高速发展,人们积累的数据量急剧增长,动辄以Mbytes 计,如何从海量的数据中提取有用的知识成为当务之急。数据挖掘就是为顺应这种需要应运而生发展起来的数据处理技术,是知识发现(knowledgediscovery in database)的关键步骤[1]。
计算机数据挖掘技术最早源于人工智能学习,于20 世纪 80 年代末逐渐开始发展,在各个领域的应用都取得良好的成果。它是目前解决海量数据分析、归纳、总结的有效途径之一。它的基本过程如图 1 所示。
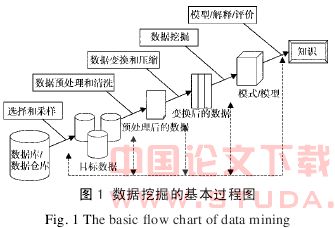
在数据挖掘的准备阶段,需要完成数据的选择和采样、挖掘目标的确定;在数据挖掘的实施阶段,需要根据挖掘的目标进行数据的预处理和变换成易于挖掘的指标,以形成模式或模型;在数据挖掘的验证阶段,需要用数据验证挖掘得到的知识的可靠性和适用性。同时,数据挖掘是风险分析的数据基础,数据挖掘可以得到直接用于风险定量分析的大量数据,使风险判断更为科学准确。
1 数据挖掘的概念和方法
1.1 数据挖掘的方法
目前最常用的的数据挖掘方法有 6 种①神经网络方法,其缺点是“黑箱”性,人们难以理解网络的学习和决策过程。②遗传算法,该算法较复杂,收敛于局部极小的较早收敛问题尚未解决。③决策树方法,它的主要问题是:复杂概念的表达困难;同性间的相互关系强调不够;抗噪性差。④粗集方法,由于粗集的数学基础是集合论,难以直接处理连续的属性。而现实信息表中连续属性是普遍存在的。⑤统计分析方法,即利用统计学原理对数据库中的信息进行分析。⑥模糊集方法,即利用模糊集合理论对实际问题进行模糊评判、模糊决策、模糊模式识别和模糊聚类分析。一般模糊集合理论是用隶属度来刻画模糊事物的亦此亦彼性的。由于本文是针对大量确定性数据进行挖掘,因此适合采用统计分析法。
1.2 数据挖掘目标的确定
根据所采集的数据样本大小,本文以基坑稳定状态与测斜监测数据之间的相对关系作为数据挖掘的目标。以基坑工程的风险等级判断为目标,可分为以下3 种不同风险等级:
(1) 基坑放置期间的基本稳定平衡状态;
(2) 工程危险时的不可控失稳状态;
(3) 介于前两者之间的的危险但可控状态;其中基本稳定平衡状态最为常见,而工程危险相对其它两种状态发生的概率较小。
1.3 数据的选择和采样
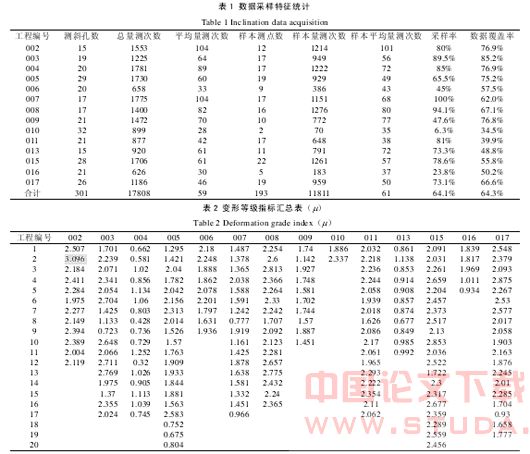
兼顾数据的代表性、普遍性及有效性,对系统采集到的 17 个工程共 356 个测斜管的监测数据汇总,剔除其中有效数据量小于 26 天和明显无数据规律的测斜管数据,以余下的 193 孔共 11811 天次测斜管数据为供数据挖掘的样本数据。见表 1 所示。
2 基坑工程数据挖掘与风险识别
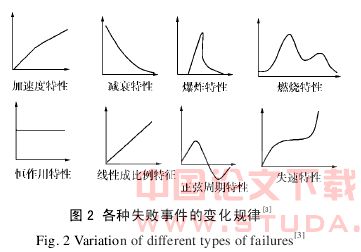
如上所述,基坑工程的风险预兆与监测数据的变化密切相关,通过对监测数据的挖掘分析,可以找到其内在联系的量化指标,从而及时识别基坑的风险状态。从变形角度看,基坑的风险状态表现为以下几种具体形式:基坑坍塌、滑坡失稳,挡土墙变形过大及踢脚等[2]。从系统角度来看,不同工程系统表现的失效模式或规律是不一样的(图 2 所示)。对基坑工程系统而言,失效前变形数据的加速变化被证实为风险的预兆。
基坑的理想稳定状态的特征可以采用其内在的力学平衡状态来表征。即以基本数据为依据,构成原始尺度、比较条件、设定条件、最优方案,继而构成一个几乎不发生风险的系统,并组成一个理想的无风险的系统模型。实际上它可以通过力学方法求得,如通过一般杆系有限元方法求得。基坑实际发生的变形(浮动状态)相对于理论计算变形(理想状态)的偏移可以看作对稳定状态的偏移(如图 3 所示)。从大量工程实践来看,实际基坑工程对稳定状态的偏移并不是以其绝对偏移数值来判断,而是以偏移的速率(即变形加速度)来及时识别潜在风险的存在,这对于工程具有更大的实际意义。
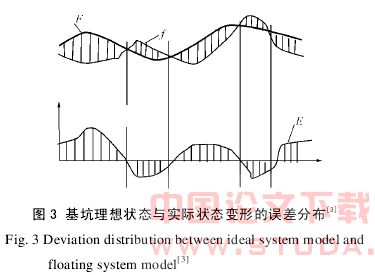
将评估对象的实测参数,经过数据挖掘转化,构成评估对象的浮动状态模型(可调控的模型)[3]。以基坑理想状态的模型为主,以实际观测到的浮动模型为辅,对 2 个模型进行误差对比、误差分离,可采用下式进行:F(N1,N2,…,Nn-1)-f(n1,n2,…,nn 1)=E(el,e2,…,en l),式中,F 项表示理想模型;f项表示浮动模型;E 项表示二者的误差。图 3 中的正误差说明基坑的浮动模型正向偏离理想状态模型的设定值,而负误差则说明被基坑系统的浮动模型超越了理想系统,基坑工程存在风险的可能性大,误差值越大风险越大。
2.1 风险指标的确定
根据文献、工程经验和工程危险反映出的数据变化特征,本次研究以测斜的最大值、最大变形速率作为挖掘的主要指标。
2.2 测斜最大绝对值的数据挖掘
由于各个基坑的开挖深度不同,各个基坑之间不能直接用测斜的最大绝对数值进行比较。所以,根据《上海地铁基坑工程施工规程》的对上海地铁基坑工程安全控制指标规定,提取样本数据的历史最大绝对变形量,将其归一化为相对于开挖深度的无量纲变形等级指标(μ),以考量基坑变形等级与工程危险之间的关系。定义如下
μ = 1 ( D -D1 )/ D1 , (D ≤D1);
μ = 2 (D - D1 )/( D 2 - D1 ), ( D 1 < D ≤D2);
μ = 3 (D - D1 )/( D 3 - D2 ), (D 2 < D ≤D3);
μ = 3 D / D3 , ( D 3<D)。
式中 D 为测斜最大变形;D1为一级基坑测斜变形控制指标;D2为二级基坑测斜变形控制指标;D3为三级基坑测斜变形控制指标。
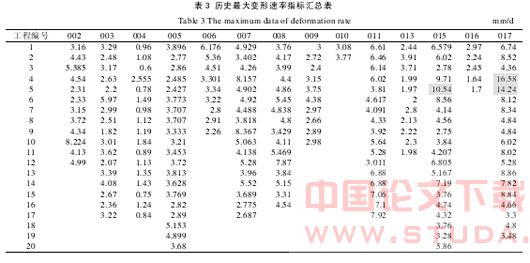
2.3 测斜最大变形速率的数据挖掘
考察测斜的历史最大变形速率,经汇总得到表 3。从表 3 中发现,发生工程危险的 017 工程的 C04、C05孔,正是历史最大变形速率最大的两个孔,由此可以认为最大变形速率与基坑状态之间,存在较为明显的联系。此外,将样本数据的测斜最大变形速率,以 0.1mm/d 为间隔,根据其发生的频率绘制分布见图 4。
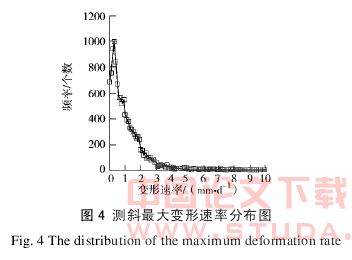
从图 4 中可以发现,测斜最大变形速率集中在 0.3mm/d 附近,而超过 4 mm/d 的数据有 218 个,占总数据量的 1.85%;超过 5 mm/d 的数据有 96 个,占总数据量的 0.81%;而超过 10 mm/d 的数据仅有 3 例。这个统计结果与工程危险相对工程安全状态出现概率较少的情况相符。参照施工工况的相关数据和工程危险事例,发现基坑在放置阶段,变形速率最大不超过 1mm/d;危险情况下,变形速率大于 10 mm/d;对于基本稳定平衡、正常施工的危险可控状态和具有工程危险征兆的不可控失稳状态,这 3 种基坑的状态对应的最大变形速率存在量级的区别。由此,可以建立最大变形速率和基坑状态的直接联系。
3 数据挖掘成果及风险阀值的确定
根据前面数据挖掘的成果,在一定变形等级下,采用测斜最大变形速率比采用测斜最大变形值来判断基坑的危险更加准确。但是,对测斜最大变形速率,选取什么样的控制指标来作为基坑风险判断的阀值,以及控制指标的实用性显得十分重要,还必须作进一步分析。
原文网址:http://www.pipcn.com/research/200808/8963.htm
也许您还喜欢阅读: